.avif)
AI Reading Group | How Far is Video Generation from World Model: A Physical Law Perspective


How Far is Video Generation from World Model: A Physical Law Perspective
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, Jiashi Feng
We close out this season of the BLISS Reading Group with a critical question that follows naturally from the previous two sessions: when a video generation model produces realistic-looking physics, has it actually learned the underlying laws?
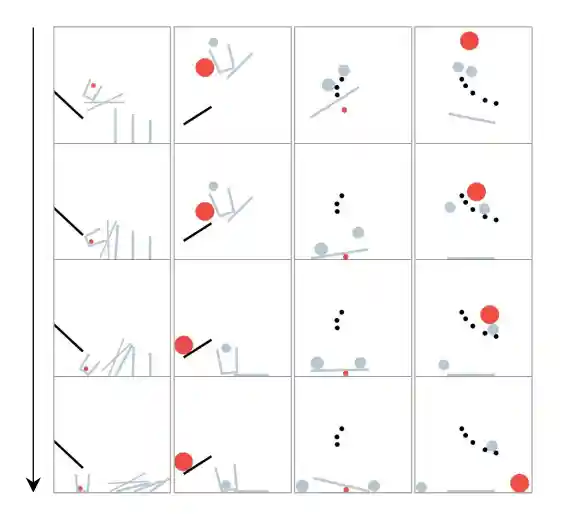
Our paper is How Far is Video Generation from World Model: A Physical Law Perspective (Kang et al., 2024).
After Sora and similar models generated impressive videos that appeared to obey physics, it became tempting to claim that scaling video generation would naturally produce world models. Kang et al. put this to the test. The results are sobering: the models generalise perfectly in-distribution, show some scaling progress on combinatorial tasks, but fail on out-of-distribution scenarios. Naive scaling alone is not enough to discover physical laws.
What would it take for a video model to truly extrapolate rather than interpolate? Is combinatorial diversity in training data the answer, or do we need fundamentally different architectures? And does a "world model" need to learn laws, or is good-enough prediction sufficient?
.avif)
.avif)

Become a part of the AI Campus.
There are many ways to join our community. Sign up to our newsletter below, or select one of the other two options and get in touch with us: